Chapter 2 データの読み込み
本報告では Fukuda, Yoda, and Mogi (2021) のSupplemental Tableとして掲載されているデータを用いる。これは「国勢調査」の調査票情報を用いて、妻が30-39歳の夫婦の学歴組み合わせを示すクロス集計表である。例えば、以下は1980年の「国勢調査」にもとづく夫婦の学歴組み合わせである。
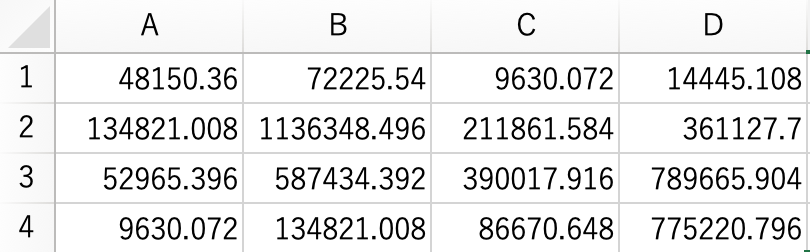
## EduH
## EduW JHS HS VC/JC UNI
## JHS 1825957.2 692306.05 25961.477 43269.13
## HS 744229.0 3106723.41 164422.687 856728.74
## VC/JC 34615.3 207691.82 69230.605 493268.06
## UNI 0.0 25961.48 8653.826 337499.20表側には妻の学歴(EduW)、表頭には夫の学歴(EduH)がそれぞれ置かれている。ここに調査年(CensusYear)を追加すると、妻の学歴×夫の学歴×調査年の3変数からなる多元クロス集計表を作成することができる。
本報告では、上のようなクロス集計表のデータが事前に与えられている状況を想定して進めていく。具体的には、「国勢調査」の調査年別に\(4\times4=16\)セルの度数がCSVファイルなどで与えられているものとする。そのため、以下ではCSVファイルの出入力の基本操作を押さえておこう。
2.1 CSVファイルの読み込み
まず、本報告で用いるCSVファイルはCensusCSV/CSV_EduWHフォルダに保存されている。ここには1980年、1990年、2000年、2010年の「国勢調査」を用いて集計された夫婦の学歴組み合わせのデータファイルが調査年ごとに保存されている。例えば、以下は1980年調査のデータファイルである1。
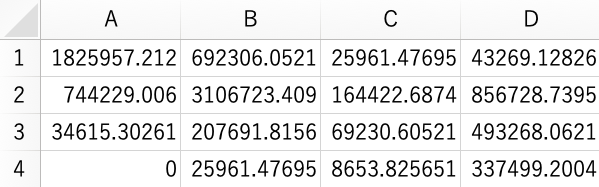
夫婦の学歴組み合わせ:1980年
CSVファイルの読み込みにはread.csv()を用いる。この関数に最低限必要な引数は、読み込みの対象となるCSVファイルのパス(file)である。CSVファイルがワーキングディレクトリと同じ階層に保存されている場合はファイル名を文字列で引き渡せばよい。CSVファイルが異なる階層に保存されている場合は、相対パスあるいはフルパスでファイルの場所を指定する。その際、報告者個人が推奨する方法は、CSVファイルが保存されているフォルダのパスをオブジェクトと保存しておき、そのオブジェクトとファイル名の文字列とをpaste()あるいはpaste0()で結合する方法である2。このようにしておくと、CSVファイルの保存場所が変更された場合でも、そのフォルダパスを示すオブジェクトのみを修正すればそれ以外のコードを修正する必要がないためである。
また、今回の例には当てはまらないが、1行目が変数名となっている場合は、header = TRUEとすると(むしろ、こちらがデフォルトの設定)1行目は変数名として処理され、2行目からobservationとして認識される。
CensusDir <- "CensusCSV/CSV_EduWH/"
FN_EduWH1980csv <- paste0(CensusDir, "EduWH1980.csv")
EduWH1980_raw <- read.csv(file = FN_EduWH1980csv, header = FALSE) # "file = "は省略可read.csv()でデータを読み込んだ直後のオブジェクトの型はデータフレームになっている。今回raw dataとして読み込んだのは行列の形をしたクロス集計表であるため、以下のように行列に変換する必要がある。
# CSVファイルを読み込んだ直後の型はデータフレームになっている
class(EduWH1980_raw) ## [1] "data.frame"# as.matrix()でオブジェクトの型を行列に変換
EduWH1980_mat <- as.matrix(EduWH1980_raw)
class(EduWH1980_mat)## [1] "matrix" "array"EduWH1980_mat## V1 V2 V3 V4
## [1,] 1825957.2 692306.05 25961.477 43269.13
## [2,] 744229.0 3106723.41 164422.687 856728.74
## [3,] 34615.3 207691.82 69230.605 493268.06
## [4,] 0.0 25961.48 8653.826 337499.20こうしてデータの型をデータフレームから行列に変換できたものの、この段階では各行および各列がそれぞれどのカテゴリを示すのかが明瞭ではない。そこで、dimnames()を用いて行列の次元にラベルをつけておくと便利である。dimnames()はオブジェクトの各次元のラベルをリスト(list)として返す関数である。
EduWH1980 <- EduWH1980_mat
class(dimnames(EduWH1980))## [1] "list"dimnames(EduWH1980)## [[1]]
## NULL
##
## [[2]]
## [1] "V1" "V2" "V3" "V4"列(column)のラベル(“V1”-“V4”)のみが保存されており、行ラベルは空であることがわかる。夫婦の学歴カテゴリを示すラベルを付与するためには以下のようにリストとして代入する。
dimnames(EduWH1980) <- list(c("JHS", "HS", "VC/JC", "UNI"),
c("JHS", "HS", "VC/JC", "UNI"))
EduWH1980## JHS HS VC/JC UNI
## JHS 1825957.2 692306.05 25961.477 43269.13
## HS 744229.0 3106723.41 164422.687 856728.74
## VC/JC 34615.3 207691.82 69230.605 493268.06
## UNI 0.0 25961.48 8653.826 337499.20行カテゴリ・列カテゴリが付与されたが、さらにnames()とdimnames()とを組み合わせることで行方向・列方向それぞれの変数名も付与できる。
names(dimnames(EduWH1980)) <- c("EduW", "EduH")
# 完成!
EduWH1980## EduH
## EduW JHS HS VC/JC UNI
## JHS 1825957.2 692306.05 25961.477 43269.13
## HS 744229.0 3106723.41 164422.687 856728.74
## VC/JC 34615.3 207691.82 69230.605 493268.06
## UNI 0.0 25961.48 8653.826 337499.202.2 CSVファイルの出力
つづいて、Rの上で作成したオブジェクトを外部ファイルに出力する方法について見ておこう。オブジェクトはさまざまなフォーマットで出力可能であるが、ここではCSVファイルの出力方法について説明する。
2.2.1 出力するオブジェクトの準備
前節ではすでに調査年ごとのクロス集計表がCSVファイルの形式で用意されていることを前提に、CSVファイルを読み込む方法を見てきた。しかしながら、Fukuda, Yoda, and Mogi (2021) で公表されているのは、以下のように、調査年ごとの夫婦学歴組み合わせのクロス集計表の全体度数と全体パーセントのみである。
Fukuda et al.(2021)
そこで、これらの情報に基づいてクロス集計表のセル度数を算出し、それらをCSVファイルに出力してみよう。例として2010年のクロス集計表を取り上げる。まず、以下のように全体パーセントを入力したデータをCSVファイルとして保存しておく。
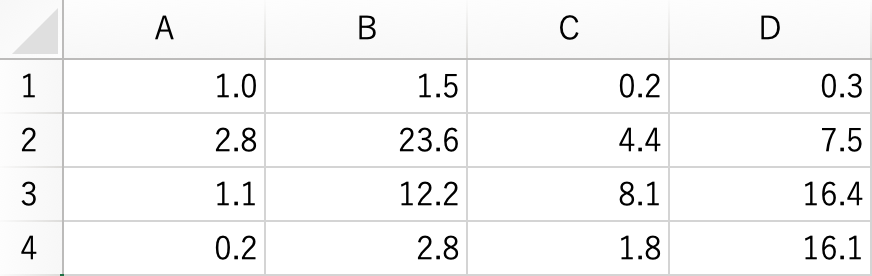
2010年のクロス集計表(全体パーセント):TotProp2010.csv
つぎに、このCSVファイルをRに取り込んでおく。
# パラメータの設定
SupTabsDir <- "CensusCSV/SupplementalTables/" # 全体パーセントのCSVファイルが保存されているディレクトリ
OutDir <- "CensusCSV/CSV_EduWH/" # 出力先ディレクトリ
NofObs <- 481536 # 全体度数
# 全体パーセントの読み込み
TotProp2010_raw <- read.csv(paste0(SupTabsDir, "TotProp2010.csv"), header = FALSE)
TotProp2010 <- as.matrix(TotProp2010_raw)
TotProp2010## V1 V2 V3 V4
## [1,] 1.0 1.5 0.2 0.3
## [2,] 2.8 23.6 4.4 7.5
## [3,] 1.1 12.2 8.1 16.4
## [4,] 0.2 2.8 1.8 16.1クロス集計表の全体パーセントを行列として読み込めたら、あとはそれらを比率に変換した上で全体度数を乗じればセル度数が得られるので、
# セル度数の算出
EduWH2010 <- NofObs * (TotProp2010 / 100)
EduWH2010## V1 V2 V3 V4
## [1,] 4815.360 7223.04 963.072 1444.608
## [2,] 13483.008 113642.50 21187.584 36115.200
## [3,] 5296.896 58747.39 39004.416 78971.904
## [4,] 963.072 13483.01 8667.648 77527.296とすれば、2010年の夫婦の学歴組み合わせのクロス集計表が得られる。
2.2.2 write.csv()
CSVファイルを出力するための関数のひとつがwrite.csv()である。第1の引数として保存するオブジェクト名を指定し、fileには保存するファイル名を(パスも含めて)指定する。row.names = FALSEを指定しないと、第1列目に行ラベル(ない場合は行番号)が表示される。
write.csv(EduWH2010, file = paste0(OutDir, "EduWH2010_writecsv.csv"), row.names = FALSE)保存されたCSVファイルを開いてみると、第1行目に列名(変数名)が表示されていることがわかる。このままでも必要な情報(セル度数)は保存されているので大きな問題ではないが、列名も表示させたくない場合はwrite.table()を使うと良い。
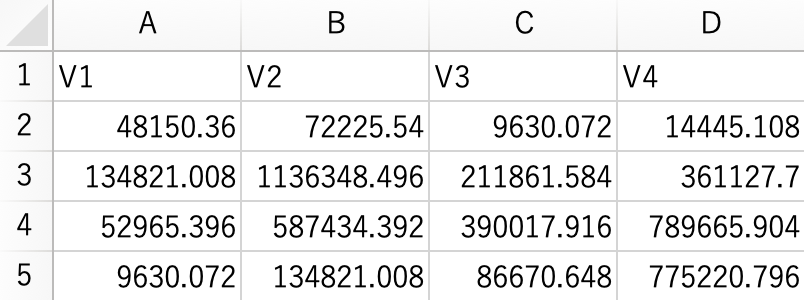
write.csv()で出力されたCSV